Google's algorithm updates typically arrive unheralded. Traffic moves, rankings shift or crash, and marketers panic. With the February 2026 Discover Core Update, Google explicitly stated its intentions, and what it said tells us a lot about how to build search authority moving forward.
The February 2026 Google Discover Core Update
TL;DR:
On February 5, 2026, Google announced the first core update ever scoped exclusively to Google Discover. Google Discover is a personalized content feed that preemptively surfaces articles based on a user's interests before they initiate a query. The update rolled out over two weeks to English-language users in the US, with a global expansion planned in the months ahead. Google stated three priorities:
-
-
Show users more locally relevant content from publishers based in their country.
-
Reduce sensationalist and clickbait content.
-
Surface more original, in-depth content from sites that demonstrate genuine expertise in a specific subject area.
That third point may be the most impactful, because it advances a concept most marketers are probably familiar with. Google has used E-E-A-T (experience, expertise, authoritativeness, and trustworthiness) as a content quality framework for years. This update changes the unit of measurement.
E-E-A-T used to function roughly at the domain level. A site with strong overall authority carried it across everything it published. The February 2026 update significantly tightens the aperture. Google now evaluates expertise by content cluster, meaning authority is earned and assessed topic by topic. A site with impressive domain metrics but shallow coverage of a subject gets no credit for it in Discover. A site with modest overall authority but deep, consistent coverage of a specific area can outperform it.
That impacts content strategy in two ways. Editorially: what you cover, how deeply you cover it, and whether your content contributes something a generative AI system couldn't produce on its own. The second is technical: how you structure your expertise so Google's systems can actually recognize and classify it. Both matter, and neither works well without the other.
The update applies to Discover, but the factors it rewards are the same ones shaping search visibility across every channel. Discover is worth understanding, but it's a personalized feed that depends on topic interest density. If your topic doesn't have enough users actively following it in Discover, the feed won't generate meaningful volume regardless of your entity authority. Recommendation engines are audience-dependent by design. A B2C company in a highly specialized field and a B2B brand are in the same position here. Discover may not be relevant for either, but establishing entity authority is.
Discover Core Update, Explained
Google's Discover feed operates on fundamentally different logic than search. When someone types a query, they're telling Google what they want. Discover works the other way around. It infers what a user will find valuable based on their interests and behavior, then surfaces content before they ask for it. That makes the February 2026 update significant in a way that goes beyond traffic fluctuations. Google isn't just adjusting how it ranks pages in response to queries. It's changing how it decides what content is worth recommending to people who didn't ask for anything.
The three stated changes are worth examining individually. The local relevance priority means publishers based in a user's country will receive preferential treatment in that country's Discover feed. For US-based publishers, this is a tailwind. For international publishers targeting US audiences, it's a headwind that will likely intensify as the update expands globally.
The clickbait reduction is the most straightforward of the three. Google updated its Discover documentation to explicitly flag misleading titles, withheld information, and content that exploits morbid curiosity or outrage as disqualifying signals. Publishers who built Discover traffic on sensationalist packaging are the obvious losers here. For publishers focused on substantive content, it mostly clears the competitive field.
The third change is the most consequential and the least self-explanatory. Google said it would prioritize content from sites with demonstrated expertise in a given area, based on its systems' understanding of a site's content. It means Google is making an active assessment of what topics a site genuinely covers with depth, and using that assessment to determine eligibility for Discover placement. A site doesn't get recommended for a topic just by publishing something about that topic, but rather, because Google has classified it as an authoritative source within that topic space.
The February 2026 update is one expression of a longer migration. Google has been moving for years from a passive index toward an active recommendation engine that surfaces content based on what it believes you'll find valuable. Discover is the purest form of that model, and this update is Google raising the bar on what qualifies as a trustworthy recommendation. Publishers who built authority around specific ideas rather than broad topic coverage are the ones positioned to benefit. Those who treated content as a volume game, spreading coverage thin across whatever was searchable, are the ones with the most to lose as the update expands globally.
How Google Rewards Entity Authority
To understand what Google is actually classifying and prioritizing, it helps to understand how its systems have learned to read content. For most of search's history, Google matched strings of text, keywords on a page against keywords in a query. That worked well enough until the web became saturated with content engineered to exploit it, rendering it almost useless to users.
The Knowledge Graph, introduced in 2012, was Google's move toward something more durable. Instead of matching strings of text, it began identifying things: people, organizations, products, concepts, and mapping the relationships between them. Google calls these things entities. When you search for a company and a knowledge panel appears on the right side of the results page, that's the Knowledge Graph at work. Google has already classified that company as a structured object with defined attributes: what it does, what category it belongs to, what topics it connects to. The database behind that panel now contains approximately 54 billion entities and 1.6 trillion facts, and it's what Google's systems consult when deciding whether a publisher genuinely belongs in a topic space.
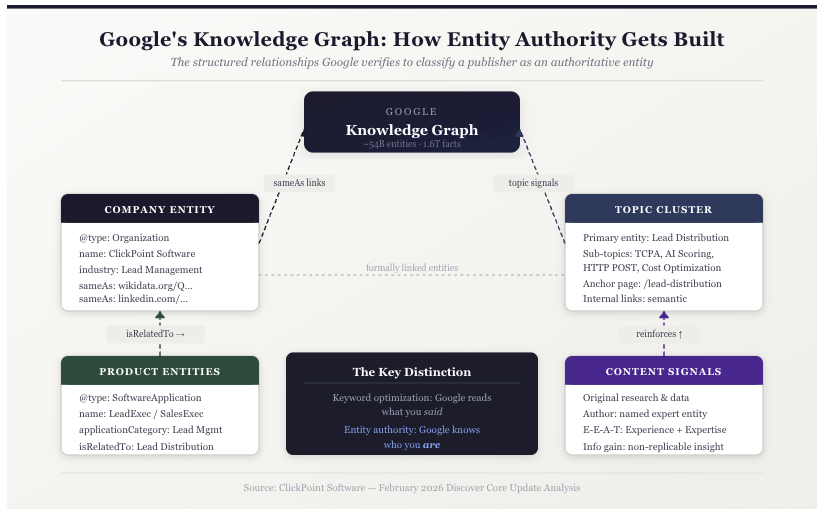
For publishers, the practical implication is significant. A page that ranks well because it contains the right keywords is playing a different game than a page that ranks because Google has classified the publishing site as an authoritative entity within a specific topic space. The first can be displaced by any competitor willing to optimize more aggressively. The second is harder to move, because it reflects Google's structural understanding of who you are, not just what you said.
Entities extend beyond topics and content clusters. Your company is an entity. Your products are entities. And crucially, those entities can be explicitly connected in Google's Knowledge Graph to the topic entities you're building authority around. A company like ClickPoint, where I serve as CMO, publishes authoritative content about lead management and distribution and structures its schema markup so that its products are formally linked to that concept. That's categorically different from a company that simply mentions its product in relevant articles. One is building a content strategy. The other is building a knowledge architecture.
"Entity authority is the difference between Google knowing what you said and Google knowing who you are."
The February 2026 update rewards the latter. Google's ability to classify a site as an authoritative source within a topic space depends on how clearly it can understand what that site is, what it offers, and how those things relate to the concepts it covers. That understanding doesn't come from reading your content alone. It comes from structured signals that tell Google's systems exactly who you are and where you fit.
How to Build Entity Authority: The Technical Layer
Building entity authority requires two things working in parallel: structured data and site architecture that reinforces that identity through every page you publish.
The starting point is schema markup, specifically JSON-LD, the format Google recommends for structured data. Schema markup is structured code added to a webpage that explicitly tells Google what the page is about, who published it, and what entities it contains. Think of it as a TLDR for Google. Schema quickly tells it what the content means, so it doesn't have to work it out for itself.
Basic implementation identifies your company as an organization or tags an article with its author and date. Entity-oriented implementation goes further, using the @graph property to define multiple related entities in a single block and declare the relationships between them. The relationships are stated, not inferred.
The second element is sameAs linking, which connects your company entity to its corresponding records in trusted external databases, such as Wikidata, Wikipedia, and LinkedIn. This removes ambiguity about who you are. For a company operating in a competitive topic space, it's the difference between Google treating your brand as a verified entity with defined attributes and treating it as an unverified name that appears in content.
The third element is semantic internal linking. Every article covering a subtopic should link back to the primary page that defines your authority in that space, using anchor text that describes the conceptual relationship rather than just the destination. This signals to Google that your coverage of a topic is deliberate and interconnected, not a collection of loosely related pages.
The most consequential implementation, and the one most companies skip, is connecting your product or service as a named entity to the topic clusters you're building authority around. At ClickPoint, we structure our schema so that our lead distribution products are formally linked to the lead distribution topic cluster we publish around. When Google has already classified your product as a formally linked entity within a topic space, the nature of that relationship is structural. It goes beyond having published relevant content.

The Editorial Layer: Content Google's AI Can't Replicate
The technical layer establishes who you are in Google's systems. The editorial layer establishes why that classification should be trusted. Both matter, but no schema implementation compensates for regurgitated content that has nothing original to say.
Google's February 2026 update explicitly rewards original, in-depth content from sites with demonstrated expertise. The web in 2026 is saturated with competent, well-structured, topically relevant content produced industrially by AI systems. It covers the fundamentals thoroughly, hits the right semantic clusters, and passes most readability benchmarks. The problem is that it's all drawing from the same pool of existing knowledge. It recombines what's already there. It doesn't add to it. Furthermore, it's frequently limited, poorly written, and inaccurate.
When AI-generated content gets published without meaningful editorial judgment, it gets indexed, crawled, and fed back into the models that produced it. The output trains the next output. I've started calling this the inhuman centipede, a system consuming its own waste. The result is content that looks increasingly similar, amplifies existing errors, and drifts further from anything a real practitioner would recognize as accurate or useful. The February 2026 update is, in part, Google's response to that.
What AI systems cannot replicate is information gain. The concept comes from information theory, but the practical definition is straightforward: content with high information gain reduces a reader's uncertainty about a subject by providing something they couldn't have found by reading existing sources. Original research, proprietary data, practitioner interviews, and documented first-hand experience all generate information gain. A summary of what others have already written doesn't.
Here's what makes this moment genuinely interesting for writers and marketers who care about their craft: for most of the past decade, good writing and good SEO were often in conflict. Keyword density requirements padded sentences. Optimal word counts pushed writers to say in two thousand words what they could have said in eight hundred. Readability scores rewarded simple sentences and penalized complexity, dumbing down content written for an intelligent audience. The mechanics of traditional SEO created incentives that actively punished clarity, specificity, and voice.
"The mechanics of traditional SEO created incentives that actively punished clarity, specificity, and voice."
An article written the way this one is written would have failed most SEO audits in 2024. The opposite is now true. The signals Google is now optimizing for, original insight, demonstrated experience, content that couldn't have been produced by a machine working from existing sources, are the same things that make writing worth reading. For the first time in a long time, the incentive structure rewards better thinking and better writing.
For content marketers, this is a meaningful reorientation. The question to ask before publishing a piece is no longer whether a topic is searchable, but whether your organization has something genuinely original to contribute to it. That might be internal data on how customers use your product. It might be a perspective from someone in your organization who addresses the problem daily. It might be an interview with a practitioner who can speak from experience rather than from research. The format matters less than the provenance of the insight.
"The question to ask before publishing a piece is no longer whether a topic is searchable, but whether your organization has something genuinely original to contribute to it."
The content demonstrates experience. The structure confirms identity. Together they make a stronger case for topical authority than either could alone.
Entity Authority Across AI Discovery
The February 2026 Discover update is a Google update, but the underlying mechanics extend well beyond the recommendation feed. The same entity signals that determine Discover eligibility are the ones that drive citeability in AI Overviews, and the same structured relationships that make your content machine-readable for Google are what external LLMs like ChatGPT and Perplexity use to retrieve and attribute information accurately.
Search discovery has fractured into three distinct channels: traditional organic results, AI Overviews that synthesize answers at the top of the page before a user scrolls, and AI-native platforms like ChatGPT and Perplexity that operate entirely outside Google's ecosystem. Each channel has its own selection logic, but they share a common foundation. All of them favor content from sources they can verify, classify, and trust.
Google's AI Overviews draw on the same core ranking systems that power traditional search, with heavier weight on E-E-A-T signals and entity relationships. Studies tracking AI Overview sources consistently find that citations go disproportionately to sites with deep topical authority, clear authorship, and robust structured data. Surfer SEO's 2025 citation report, which analyzed 36 million AI Overviews, confirms this pattern across industries.
LLMs work differently but arrive at a similar conclusion. They develop authority based on how consistently and clearly a source is represented across their training data. Original content that other sources reference is easier for an LLM to identify as authoritative and represent accurately. The brands cited by default in ChatGPT responses about a topic are the ones that built the clearest semantic territory around it. That's the same work that builds entity authority in Google's Knowledge Graph.
Building entity authority pays off wherever your audience encounters content, including places that never involve a click. Where those returns are largest depends on your topic. For brands in narrow or technical categories, AI Overviews and LLM visibility tend to outperform Discover, which rewards audience scale as much as authority.
How to Measure Entity Authority
One of the more disorienting aspects of building entity authority is that the most commonly tracked metrics don't reveal much about whether it's working. Keyword rankings measure how well a page matches a query. They don't measure whether Google has classified your organization as a trusted entity within a topic space.
The most direct indicator is Knowledge Panel presence. Search for your brand and check whether the panel includes your industry category, related topics, and links to external records like Wikidata or LinkedIn. An incomplete or absent panel tells you where to start.
Google Search Console's Discover performance report shows which content is appearing in Discover feeds and for which topics. For consumer-facing publishers, that report is a meaningful indicator of which topic clusters Google has classified as authoritative. For publishers in specialized verticals, it's a secondary data point at best. The more relevant indicators are Knowledge Panel completeness, AI Overview citation share through tools like Authoritas or BrightEdge, and how your brand is represented when you query your target topics directly in ChatGPT or Perplexity.
Entity authority builds on a longer timeline than keyword rankings, and measurement should reflect that. The indicators are Knowledge Panel completeness, Discover impression trends for consumer-facing publishers, and AI Overview and LLM citation patterns for everyone.
Building a Reputation That Survives the Next Google Update
Every major Google update since 2022 has moved in the same direction: rewarding genuine expertise, penalizing content that exists primarily to capture search traffic, and building more structural intelligence into how it evaluates sources. The February 2026 Discover Core Update continues that trajectory.
The brands that fare best through these updates share a common characteristic. They built authority around specific ideas rather than chasing ranking opportunities, and they structured that authority in ways Google's systems can verify independently of the content itself. Entity authority is the mechanism behind that. It compounds over time in a way that keyword optimization does not, because it reflects how Google understands your organization, not just how well your pages match a query.
The practical starting point is an honest audit. Does your organization have a Wikidata record? Is your schema structured to declare relationships between your company, your products, and the topics you publish around? Do your content clusters link back to a primary page that anchors your authority in a specific subject area? These are foundational questions that most content programs haven't addressed because traditional SEO metrics don't surface the gap.
What makes this work worth doing now is that it doesn't just serve Google Discover. The same entity signals that earn Discover placement feed AI Overview citations and improve how LLMs represent your brand across platforms. Building entity authority is one of the few content investments that produces returns across every channel where your audience is forming impressions, many of which involve no click at all.
"The brands building durable authority aren't just implementing better schema. They're doing the harder work of developing genuine points of view."
There's a deeper point underneath the technical one. The brands that build durable authority in this environment aren't just implementing better schema. They're doing the harder work of developing genuine points of view on the topics they cover, coining the concepts that define those conversations, and producing content that competitors can't replicate by publishing more. When you become the source that other sources reference for a specific idea, you've built something that no algorithm update can easily displace. That's not an SEO strategy. It's the oldest form of authority there is. The incentives, for the first time in years, are finally aligned with it.
FAQ
Does this update affect me if I don't care about Google Discover traffic?
Yes. The entity signals that determine Discover eligibility are the same ones shaping traditional search rankings, AI Overview citations, and LLM visibility. Building entity authority for Discover is the same work that improves visibility across every channel. It's also worth reconsidering Discover if it fits your business profile. Discover is a powerful channel for consumer-facing brands covering topics with broad audience interest. It reaches people before they've formed a query, which means it operates earlier in the decision process than search.
How do I know if my company has a Wikidata record, and what do I do if it doesn't?
Search Wikidata.org for your company name. If a record exists, verify it includes your industry category, website, and links to your LinkedIn and Wikipedia pages. If it's incomplete, you can edit it directly. Wikidata is publicly maintained. If no record exists, you can create one. Once your record is in place, add a sameAs property to your Organization schema pointing to your Wikidata ID. That single connection is one of the clearest entity verification signals you can send Google.
What's the difference between entity authority and domain authority?
Domain authority is a site-wide score based on link equity. Entity authority is Google's assessment of how clearly it understands what your organization is, what topics it covers with genuine depth, and how those things connect to verified external records. A site can have high domain authority and low entity authority, which is increasingly the profile of sites that rank well in traditional search but struggle in Discover and AI citation systems.
Can a small or newer company build entity authority?
Yes, and often faster than an established brand. Entity authority doesn't depend on accumulating backlinks. It depends on semantic clarity, verified identity, and concentrated expertise in a specific topic area. The February 2026 update rewards depth over breadth, which favors focused publishers over sprawling content programs regardless of company size.
What's the minimum viable starting point to build entity authority?
Three steps in order. Create or claim your Wikidata record. Implement an Organization schema block on your homepage with a sameAs property pointing to that record and your key external profiles. Then identify the one topic where your organization has the deepest genuine expertise, connect your existing content around it through semantic internal linking, and designate one page as the primary authority page for that cluster. That foundation is enough to start building from.
More about AI Marketing




